

이 블로그에 담긴 내용은 순전히 개인적인 견해이며, 특정 제품이나 회사의 공식 입장을 대변하지 않습니다.
들어가며
벡터 검색을 위하여 벡터 데이터를 저장합니다. 벡터 데이터는 임베딩모델에 생성된 고차원으로 이루어진 숫자 데이터이지만 각 숫자들이 어떻게 표현되고 각 데이터간에 어떠한 유사도를 가지고 있는지 확인하기 어렵습니다. 고차원으로 이루어진 데이터를 ML알고리즘을 사용하여 2차원으로 줄여서 시각화해서 표현하면 좀더 벡터 데이터에 대해서 이해하기 쉬울것 같습니다.
오라클 데이터베이스에 내장된 ML알고리즘을 사용하여 시각화하는 방법에 대해서 알아보도록 하겠습니다.
- 사용한 ML 알고리즘 : PCA(Principal Component Analysis), K-Means(Clustering)
실습 스크립트
벡터 타입을 가진 테이블 생성을 생성합니다.
CREATE TABLE eba_vector_sample(
id NUMBER, -- Primary Key
text VARCHAR2(4000), -- 텍스트 데이터
embedding_vector VECTOR -- 텍스트 데이터에 대한 벡터 데이터
);
텍스트 데이터를 입력합니다.
INSERT INTO eba_vector_sample(id, text) VALUES
(1, '노트북을 켜자마자 이메일부터 확인하는 것이 일상이 되었다.'),
(2, '회의 중에도 노트북으로 바로 메모할 수 있어서 편리하다.'),
(3, '최근 구매한 노트북은 배터리 수명이 길어서 외출 시에도 걱정이 없다.'),
(4, '노트북의 발열 문제 때문에 쿨링 패드를 따로 구입했다.'),
(5, '프로그래밍을 할 때는 데스크탑보다 노트북이 더 익숙하다.'),
(6, '카페에서 노트북으로 작업을 하면 집중이 잘 된다.'),
(7, '노트북 화면이 작아 외부 모니터를 연결해서 사용한다.'),
(8, '재택근무 이후 노트북 사용 시간이 급격히 늘어났다.'),
(9, '노트북의 터치패드는 가끔 오작동을 일으켜서 마우스를 병행해서 쓴다.'),
(10, '노트북으로 영화 감상할 때는 이어폰을 끼는 게 몰입도가 높다.');
commit;
텍스트 데이터로부터 임베딩 모델을 호출하여 벡터 데이터를 생성합니다. 임베딩 모델은 OML4Py를 통해 Augumented된 ONNX파일을 데이터베이스에 로딩하여 사용하였습니다.
VECTOR_EMBEDDING, DBMS_VECTOR.UTL_TO_EMBEDDING함수를 사용하여 데이터베이스내에 로딩된 임베딩 모델을 사용하여 벡터데이터를 생성할수 있습니다.
UPDATE eba_vector_sample
SET embedding_vector = dbms_vector.utl_to_embedding(
data => text,
params => json('{"provider":"database","model":"MULTILINGUAL_E5_SMALL"}')
)
WHERE embedding_vector is null;
commit;
벡터 데이터 자체를 분석하기 어려우므로 각 차원의 벡터를 컬럼값으로 변경하여 데이터 분석을 위한 데이터 셋을 생성합니다. ML훈련용 데이터를 생성시 물리적인 테이블도 가능하지만 VIEW로 데이터를 가공하여 사용할수도 있습니다.
- documents_json : 벡터데이터 (데이터 벡터, 가능하면 쿼리 벡터를 조합함)
- document_vectors_flat - 벡터의 각 차원의 숫자를 컴럼으로 분리
DECLARE
l_dim INTEGER; -- 임베딩 모델 차원 개수
l_sql CLOB;
l_search VARCHAR2(4000) := '노트북을 사용하면서 불편했던 점이나 개선하고 싶은 점은 무엇인가요?'; -- Query Vector생성을 위한 질문
l_query_vector CLOB;
l_json_sql CLOB;
BEGIN
-- 1. VECTOR 데이터를 조회하여 차원 개수를 확인
SELECT VECTOR_DIMENSION_COUNT(embedding_vector), model_name
INTO l_dim
FROM eba_vector_datatable
WHERE ROWNUM = 1;
-- 2. 원본 테이블에서 데이터 분석을 위한 View를 생성
l_json_sql := 'CREATE OR REPLACE VIEW documents_json AS
SELECT id, content, ''data'' vector_type, json(embedding_vector) AS embedding_json
FROM eba_vector_datatable';
-- 2.1 검색 텍스트가 있을 경우 view에 포함.
IF l_search IS NOT NULL and length(l_search) > 0 and l_model_name is not null THEN
SELECT from_vector(dbms_vector.utl_to_embedding(
data => l_search,
params => json({"provider":"database","model":"MULTILINGUAL_E5_SMALL"})
)) INTO l_query_vector
FROM dual;
l_json_sql := l_json_sql || ' UNION ALL SELECT 999999999, '''||l_search||''', ''query'', json('''||to_char(l_query_vector)||''') FROM dual';
END IF;
EXECUTE IMMEDIATE l_json_sql;
-- 3. 벡터 데이터를 각 컬럼으로 분리하여 view로 생성
l_sql := 'CREATE OR REPLACE VIEW document_vectors_flat AS SELECT id';
FOR i IN 0 .. l_dim - 1 LOOP
l_sql := l_sql || ', JSON_VALUE(embedding_json, ''$[' || i || ']'' RETURNING NUMBER) AS v' || (i + 1);
END LOOP;
l_sql := l_sql || ' FROM documents_json';
EXECUTE IMMEDIATE l_sql;
END;
/
벡터데이터를 2차원으로 시각화하기 위하여 Principal Component Analysis알고리즘을 사용하여 차원 축소 작업을 수행합니다. PCA ML모델 생성을 위하여 파라미터를 생성후에 앞서 생성한 document_vectors_flat view르 훈련시킵니다.
BEGIN
--1. PCA모델에 대한 파라미터를 지정
EXECUTE IMMEDIATE 'DROP TABLE IF EXISTS pca_model_settings';
EXECUTE IMMEDIATE 'CREATE TABLE pca_model_settings (
setting_name VARCHAR2(30),
setting_value VARCHAR2(30))';
INSERT INTO pca_model_settings (setting_name, setting_value) VALUES
(dbms_data_mining.algo_name, dbms_data_mining.algo_singular_value_decomp),
(dbms_data_mining.prep_auto,dbms_data_mining.prep_auto_on),
(dbms_data_mining.svds_scoring_mode, dbms_data_mining.svds_scoring_pca),
(dbms_data_mining.feat_num_features,'2');
COMMIT;
--2. View데이터로부터 훈련된 PCA모델을 생성함.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('PCA_VECTOR_MODEL');
EXCEPTION
WHEN OTHERS THEN NULL;
END;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'PCA_VECTOR_MODEL',
mining_function => dbms_data_mining.FEATURE_EXTRACTION,
data_table_name => 'DOCUMENT_VECTORS_FLAT',
case_id_column_name => 'ID',
target_column_name => null,
settings_table_name => 'pca_model_settings');
-- 3. 2차원으로 축소된 View를 생성
execute immediate '
create or replace view pca_2d_vectors
as
select a.id , JSON_VALUE(vec, ''$[0]'' RETURNING NUMBER) x, JSON_VALUE(vec, ''$[1]'' RETURNING NUMBER) y
from (SELECT id,
json(vector_embedding(PCA_VECTOR_MODEL using *)) vec
FROM document_vectors_flat) a
';
END;
2개의 차원으로 축소된 데이터에서 K-Meams알고리즘을 사용하여 클러스터링 모델을 생성합니다.
BEGIN
-- 1. KMean 알고리즘을 위한 파라미터를 지정
EXECUTE IMMEDIATE 'DROP TABLE IF EXISTS KMEANS_model_SETTINGS';
EXECUTE IMMEDIATE 'CREATE TABLE KMEANS_model_SETTINGS (
setting_name VARCHAR2(30),
setting_value VARCHAR2(4000)
)';
INSERT INTO KMEANS_model_SETTINGS VALUES
(dbms_data_mining.algo_name, dbms_data_mining.ALGO_KMEANS),
(dbms_data_mining.CLUS_NUM_CLUSTERS, '5'); -- 클러스터 수 (조정 가능)
COMMIT;
-- 2. K-Means 모델을 생성함.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('KMEANS_MODEL');
EXCEPTION WHEN OTHERS THEN NULL;
END;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'KMEANS_MODEL',
mining_function => DBMS_DATA_MINING.CLUSTERING,
data_table_name => 'pca_2d_vectors',
case_id_column_name => 'ID',
target_column_name => NULL,
settings_table_name => 'KMEANS_model_SETTINGS'
);
END;
마지막으로 최종 생성된 데이터를 확인합니다.
select a.id, -- PK
b.text, -- 원본 텍스트
x, -- X값
y, -- Y값
vector_type, -- data or query 인지 구분
cluster_id(KMEANS_MODEL using a.*) as cluster_id -- clustering 구분
from pca_2d_vectors a , documents_json b
where a.id = b.id;
데이터 결과입니다.
ID TEXT X Y VECTO CLUSTER_ID
---------- ------------------------------------------------------ -------------- ------------ ----- ----------
9 노트북의 터치패드는 가끔 오작동을 일으켜서 마우스를 병행해서 쓴다. -0.185155082 -0.274914403 data 3
10 노트북으로 영화 감상할 때는 이어폰을 끼는 게 몰입도가 높다. -0.259324226 0.127383791 data 5
1 노트북을 켜자마자 이메일부터 확인하는 것이 일상이 되었다. 0.0561683723 0.0480101813 data 9
2 회의 중에도 노트북으로 바로 메모할 수 있어서 편리하다. 0.0291075716 0.121552442 data 8
3 최근 구매한 노트북은 배터리 수명이 길어서 외출 시에도 걱정이 없다. 0.0618996925 0.0133970573 data 9
4 노트북의 발열 문제 때문에 쿨링 패드를 따로 구입했다. 0.0959227296 -0.139845901 data 6
5 프로그래밍을 할 때는 데스크탑보다 노트북이 더 익숙하다. -0.0554370568 0.0758679015 data 8
6 카페에서 노트북으로 작업을 하면 집중이 잘 된다. 0.0153427279 0.0748392007 data 8
7 노트북 화면이 작아 외부 모니터를 연결해서 사용한다. -0.0623210364 -0.0165474879 data 8
8 재택근무 이후 노트북 사용 시간이 급격히 늘어났다. 0.119486936 0.0618527564 data 9
999999999 노트북을 사용하면서 불편했던 점이나 개선하고 싶은 점은 무엇인가요? 0.184309372 -0.091595539 query 6
X, Y좌표와 텍스트를 확인할수 있으므로 2차원 그래프로 시각화하면 아래와 같습니다. (아래 그램은 오라클의 로우코드 플랫폼인 APEX를 사용하였습니다. Scatter Chart로 작성되었습니다.)
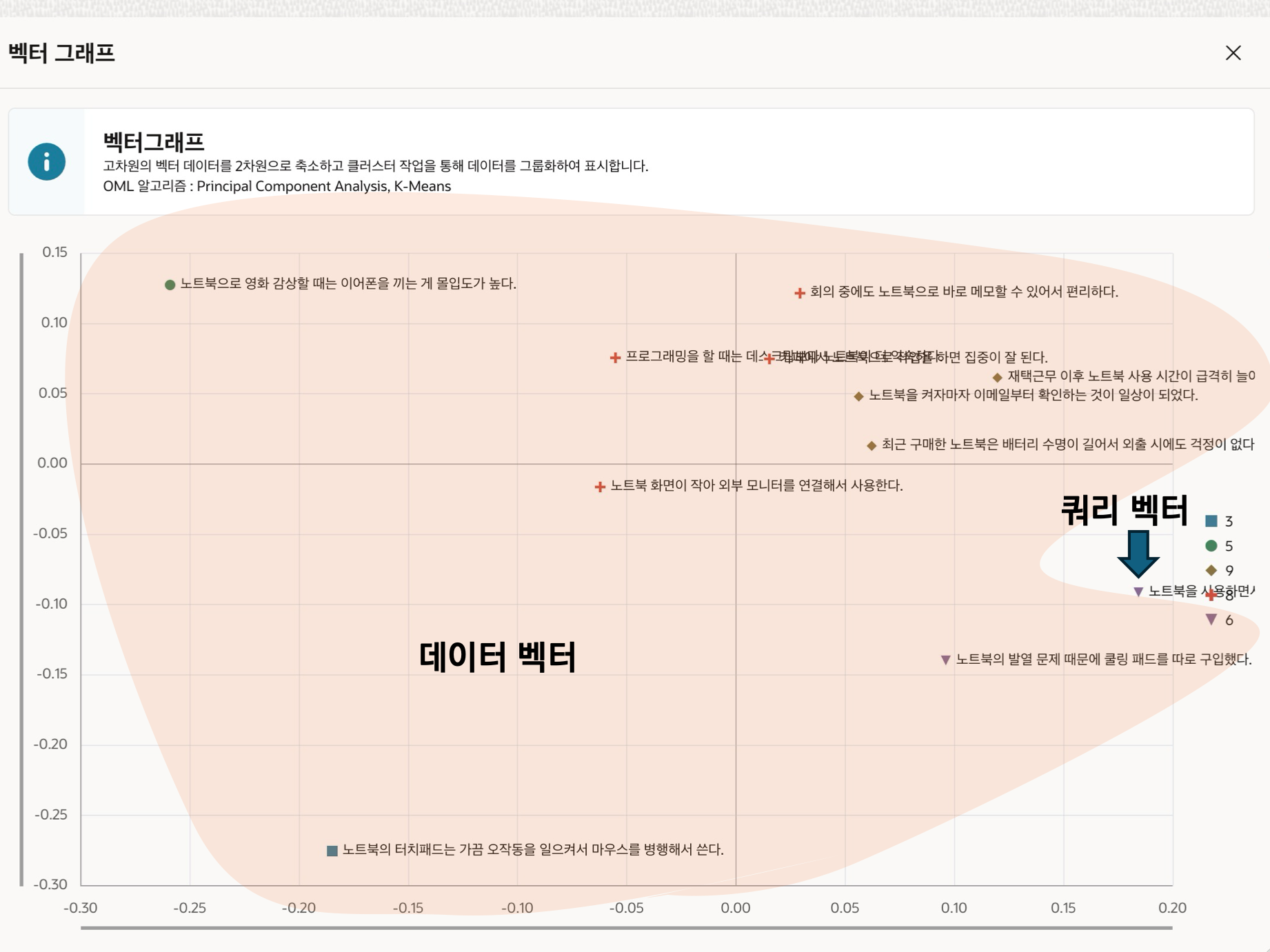
위 그래프를 통해서 확인했을때 “노트북을 사용하면서 불편했던 점이나 개선하고 싶은 점은 무엇인가요?” 질문에 가장 가까운 텍스트는 “노트북의 발열 문제 때문에 쿨링 패드를 따로 구입했다.” 이 될것입니다. 벡터 검색을 통해서 어떤 데이터가 나오는지 확인해보겠습니다.
select id, text
from eba_vector_sample
order by vector_distance(embedding_vector, dbms_vector.utl_to_embedding(
data => '노트북을 사용하면서 불편했던 점이나 개선하고 싶은 점은 무엇인가요?',
params => json('{"provider":"database","model":"MULTILINGUAL_E5_SMALL"}')
), COSINE)
fetch first 5 rows only;
데이터 결과입니다.
ID TEXT
---------- --------------------------------------------
4 노트북의 발열 문제 때문에 쿨링 패드를 따로 구입했다.
8 재택근무 이후 노트북 사용 시간이 급격히 늘어났다.
6 카페에서 노트북으로 작업을 하면 집중이 잘 된다.
1 노트북을 켜자마자 이메일부터 확인하는 것이 일상이 되었다.
3 최근 구매한 노트북은 배터리 수명이 길어서 외출 시에도 걱정이 없다.
그래프와 유사한 결과를 확인할수 있습니다. 고차원의 데이터를 축소하여 표현했기 때문에 화면에 보이는 그래프와 정확하게 일치하지 않을수 있겠습니다. 다만 내가 질문 내용과 원하는 결과의 위치를 확인하고, 임베딩 모델의 feature표현결과가 어떤지 비교할때 유용할것 같습니다.
기업내에서 임베딩 모델을 사용할때, 기업내에 있는 용어들로 fine tuning이 필요할수 있습니다. 벡터간 거리계산결과가 가장 중요한 부분이지만 임베딩 모델은 약간 블랙박스와 같이 정확하게 설명할수 없는 요소들이 있습니다. 따라서 그래프로 표현함으로써 임베딩 모델을 설명할 수 있는 데이터로 활용할수 있지 않을까 싶습니다.
마무리
오라클 데이터베이스에서 벡터 검색기능이 추가되어 백터개념들을 소개할때 유용할것 같습니다. 벡터라는 개념은 데이터 분석가들에게 친숙할수 있지만 이제 막 도입하려는 엔지니어들과 관리자에게는 아직도 어려운 개념인것 같습니다. 개념적인 내용을 시각적으로 표현하여 설명함으로써 좀 더 쉽게 이해시킬수 있지 않을까 싶습니다.
Oracle Machine Learning기능은 오라클 데이터베이스 제공되는 무료기능으로 in-DB분석을 위한 유용한 도구입니다. 데이터의 전처리 기능 및 30개이상의 ML알고리즘을 제공하여 최근에는 벡터데이터 형식과 다양한 연계기능을 제공하고 있습니다.

댓글남기기